
ListObjectsV2 is Too Slow!
This article is Day 5 of coins Advent Calendar 2025.
Building GitLFS
I was furious at GitHub’s expensive LFS pricing, so I’m developing candylfs, a GitLFS-compatible SaaS.
Needed an API/function to get object count and capacity per path. Initially did full fetch each time, but confirmed obvious slowdown as object count increased.
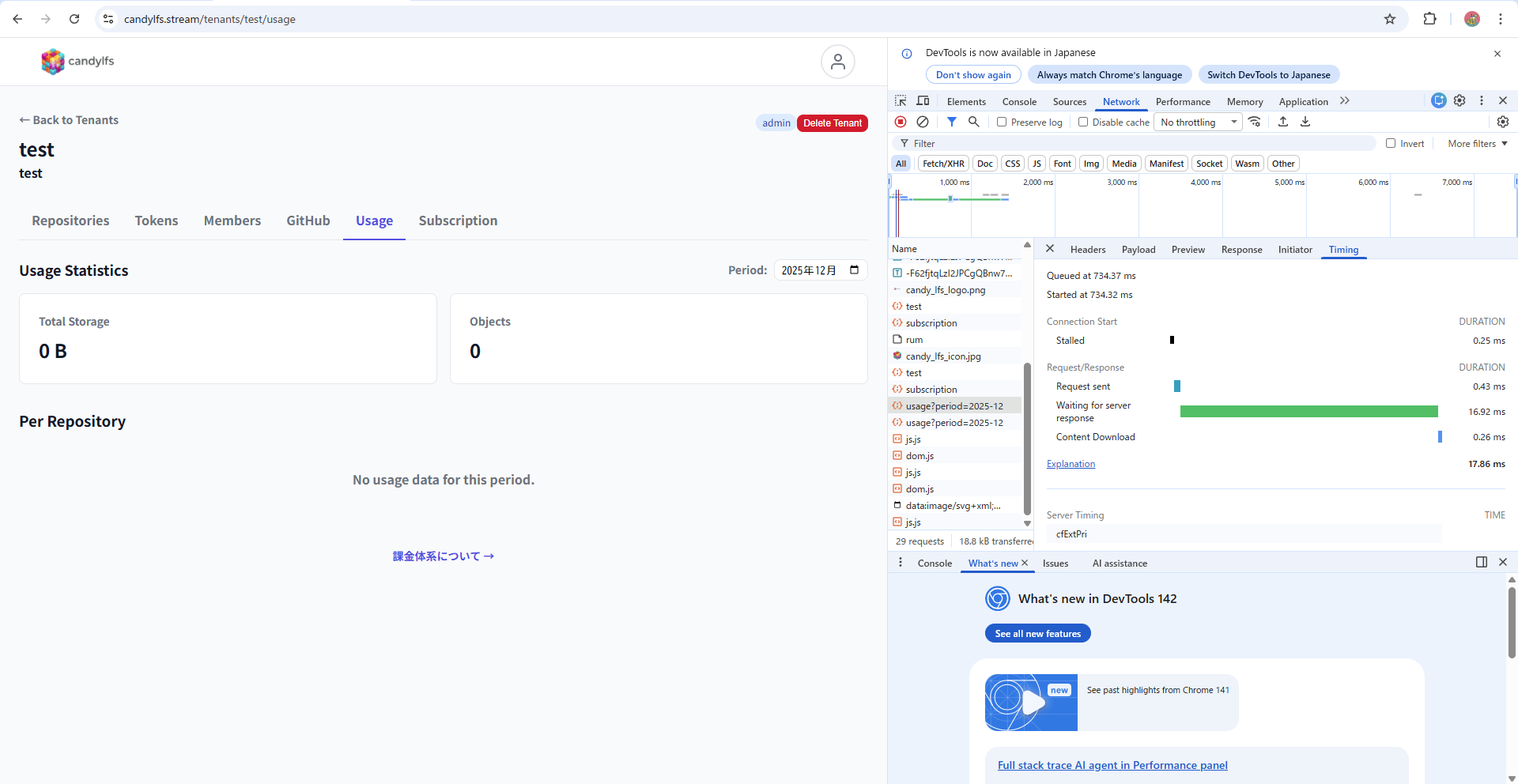
With 0 objects, ~17ms blazing fast.
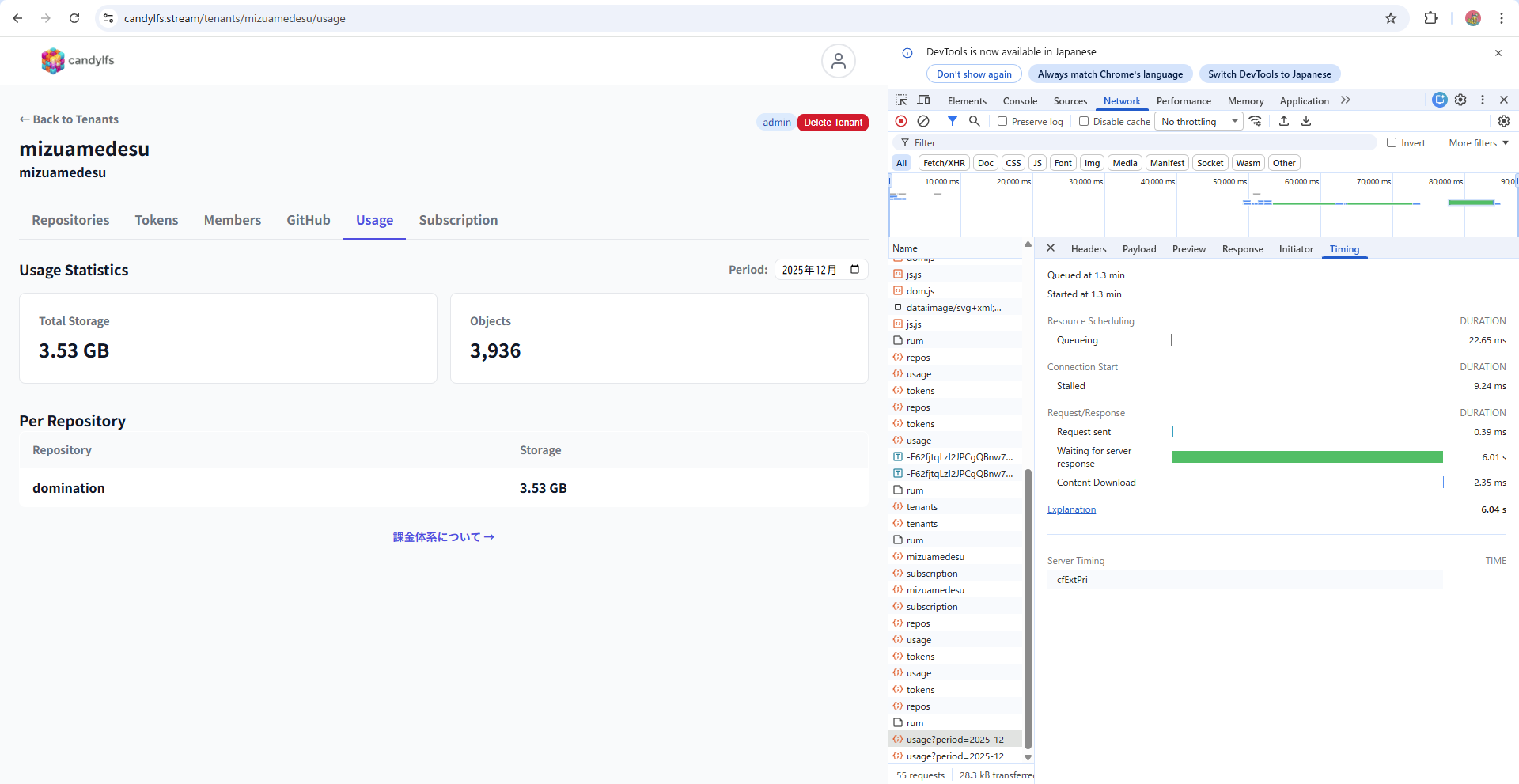
With ~4000 objects, ~6 seconds (6000ms). Noticeably slow.
CloudWatch Log Observation
Suspected ListObjectsV2 API was bottleneck, confirmed with logs.
[getSubscription] START tenantId=tenant-a
[getSubscription] Access check: 11ms
[getSubscription] DynamoDB get: 20ms
[getSubscription] S3 client init: 119ms
[getSubscription] Page 1: 1000 objects, 3121ms
[getSubscription] Page 2: 1000 objects, 2503ms
[getSubscription] Page 3: 1000 objects, 7060ms
[getSubscription] Page 4: 936 objects, 1882ms
[getSubscription] ListObjects total: 4 pages, 3936 objects, 14602ms
[getSubscription] END total: 14753ms
REPORT Duration: 14931.48 ms Memory: 148 MBSome data redacted, but this is roughly what was captured. Yes, slow. ListObjectsV2 can’t get all objects at once, pagination limited to 1000 per request. Each takes ~2-3 seconds, so 4000 objects = 4 loops = ~12 seconds.
Parallel Execution
Searched for others with this problem, found examples using prefix-based parallel execution for speedup. https://jboothomas.medium.com/fast-listing-s3-objects-from-buckets-with-millions-billions-of-items-380052fb6faf
LFS takes file hash on client upload and uses it as pointer.
All object names are saved as hash values, guaranteeing even distribution across prefixes 0123456789abcdef.
So max 16 parallel ListObjectsV2 API calls possible.
Caching
Theoretically up to 16x speed, but 16x execution cost too. So implemented DynamoDB cache. Here’s the result:
[getSubscription] START tenantId=tenant-a
[getSubscription] Access check: 12ms
[getSubscription] DynamoDB get: 74ms
[getSubscription] S3 client init: 0ms (cached)
[getSubscription] Parallel scan: 16 requests, 2925ms
[getSubscription] END total: 3012ms, 3936 objects
REPORT Duration: 3032.60 ms Memory: 155 MB[getSubscription] Parallel scan: 16 requests, 2925ms
~4x speedup achieved. Final approach: use DynamoDB cache when available, otherwise fetch with speedup method then cache.
Lambda Cost vs API Cost?
Object count/capacity needed for management console API display and quota check when client calls Batch API. Console can tolerate caching/non-realtime, but quota check needs some accuracy.
So only Batch API gets true value, but 16x cost is unacceptable. Using atomic counter in DynamoDB cache for instant client response, then fetching true value with ListObjectsV2 after.
Question: which costs more, 16 parallel API calls or Lambda runtime? Lambda at 256MB costs:
0.25 GB × 0.0000166667 USD/GB-second
= 0.000004166675 USD / secondListObjectsV2 is Class A operation at $4.5/1M calls. So 16 parallel execution:
4.5 USD / 1,000,000 × 16
= (4.5 × 16) / 1,000,000
= 72 / 1,000,000
= 0.000072 USD / callTherefore:
N = object count, MaxKeys (pagination) = 1000, assuming 2.5 seconds per call
| Item | Sequential | 16 Parallel |
|---|---|---|
| API calls | ⌈N/1000⌉ | 16 × ⌈N/16000⌉ |
| Duration | ⌈N/1000⌉ × 2.5s | ⌈N/16000⌉ × 2.5s |
Consider N = 17000 where parallel is disadvantageous:
| Item | Sequential | 16 Parallel |
|---|---|---|
| API calls | 17 | 16 × 2 = 32 |
| Duration | 42.5s | 5s |
| Lambda time cost | 0.000178 USD | 0.000021 USD |
| API cost | 0.0000765 USD | 0.000144 USD |
| Total | 0.000255 USD | 0.000165 USD |
Finding the Break-even Point
Parallel becomes disadvantageous when: shortened Lambda time cost < additional API cost.
Shortened time = Sequential time - Parallel time
Additional API = Parallel API calls - Sequential API calls × 0.0000045
Parallel loses = Shortened time × 0.0000042 < Additional API × 0.0000045| N | Sequential API | 16 Parallel API | Additional API | Shortened Time | Parallel Wins? |
|---|---|---|---|---|---|
| 1000 | 1 | 16 | +15 | 0s | Loses |
| 5000 | 5 | 16 | +11 | 10s | Wins |
| 10000 | 10 | 16 | +6 | 22.5s | Wins |
| 16000 | 16 | 16 | ±0 | 37.5s | Wins |
| 17000 | 17 | 32 | +15 | 37.5s | Wins |
Break-even point (seconds) = 1.07 × (16P - S) / (S - P)
S = ⌈N/1000⌉ (Sequential API calls)
P = ⌈N/16000⌉ (Parallel rounds)Plugging into this formula, around 5000 objects gives 2.95 seconds, so parallel is cheaper beyond this point.