Kata ContainersのSandboxChangedを解決する
TL;DR
以下はとっとと対処法を知りたい人向け
- k8s/k3sで起動したコンテナが1~2分ほどで勝手に再起動(死んで立ち直す)をする
- その際
SandboxChanged: Pod sandbox changed, it will be killed and re-createdと出る
結論
systemdとcontainer runtimeのcgroup管理の競合が発生しているため、ポッドが突然死する
ホスト側でcgroup v1を指定する必要がある。
GRUB_CMDLINE_LINUX="systemd.unified_cgroup_hierarchy=0"
sudo update-grub
sudo reboot環境
環境: k3s クラスタ、Ubuntu 24.04、Kata Containers 3.2.0 Master: i3 7100 4GB * 3 Worker: xeon 2699v4 32GB * 1
まず通常のruncでは正常に10分以上起動していた。 Kata Containersを指定すると1~2分ほどでエラーログなしにpodが消え作り直される問題が発生していた。
メモリ不足?
$ kubectl exec -it ue5-gameserver-966c8c687-9z96b -n game -- /bin/sh
$ free -h
total used free shared buff/cache available
Mem: 9.9Gi 287Mi 9.5Gi 5.0Mi 157Mi 9.5Gi
Swap: 0B 0B 0B
$ cat /proc/meminfo | grep MemTotal
MemTotal: 10416748 kB$ ps aux | grep "qemu-system-x86_64" | grep "\-m"
root 563936 53.0 2.3 ... -m 8196M,slots=10,maxmem=33006M ...ヤケクソのメモリーを割り当ててみたが、効果なし
軽量コンテナでの検証
apiVersion: v1
kind: Pod
metadata:
name: kata-test-nginx
spec:
runtimeClassName: kata
containers:
- name: nginx
image: nginx:alpine
resources:
limits:
memory: "256Mi"
---
apiVersion: v1
kind: Pod
metadata:
name: kata-test-stress
spec:
runtimeClassName: kata
containers:
- name: stress
image: polinux/stress
command: ["stress"]
args: ["--cpu", "1", "--vm", "1", "--vm-bytes", "128M", "--timeout", "3600s"]NAME READY STATUS RESTARTS AGE
kata-test-nginx 1/1 Running 0 5m7s
kata-test-stress 1/1 Running 2 5m7s # ← 2回再起動
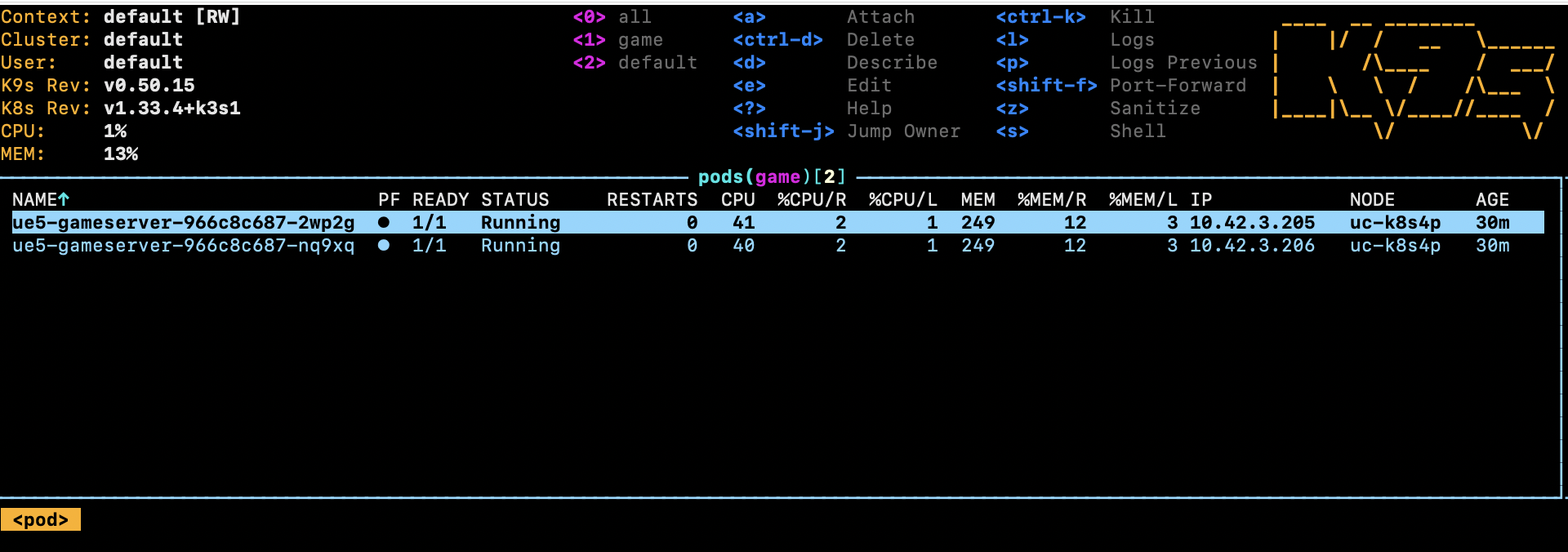
ue5-gameserver-966c8c687-7m85p 1/1 Running 5 13m # ← 5回再起動
ue5-gameserver-966c8c687-twhxr 1/1 Running 3 13m # ← 3回再起動軽量な方は落ちていなかったが、高負荷のものは落ちた。 UnrealEngineのdedicatedサーバーを最初動かしていたのだが、UEの問題なのかk3s側の問題なのか切り分けがしたかった。結果はk3s側の問題と分かった。
ログ
$ kubectl describe pod ue5-gameserver-966c8c687-qz4sn -n game | grep -A 10 "Events:"
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m3s default-scheduler Successfully assigned game/ue5-gameserver-966c8c687-qz4sn to uc-k8s4p
Normal Killing 49s kubelet Stopping container gameserver
Normal SandboxChanged 48s kubelet Pod sandbox changed, it will be killed and re-created.
Normal Pulled 47s (x2 over 2m1s) kubelet Container image "ue-server-env:latest" already present on machine
Normal Created 47s (x2 over 2m1s) kubelet Created container: gameserver
Normal Started 46s (x2 over 2m1s) kubelet Started container gameserverSandboxChangedで死んでるとわかる。
カーネルログをみたが何もエラーがない。
Kata ログ確認
$ sudo journalctl -u k3s-agent --since "10 minutes ago" | grep "9f04f8b941e445c5" | tail -50
Oct 12 04:19:50 uc-k8s4p kata[556809]: time="2025-10-12T04:19:50.989892702Z" level=warning msg="Could not add /dev/mshv to the devices cgroup" name=containerd-shim-v2 pid=556809 sandbox=9f04f8b941e445c5...
Oct 12 04:21:06 uc-k8s4p k3s[556210]: I1012 04:21:06.672345 556210 pod_container_deletor.go:80] "Container not found in pod's containers" containerID="9f04f8b941e445c5..."ガチで急にコンテナが消えている。
時代はインターネット
ブチギレていた所、先人の神が同様の問題の原因と解決策を載せてくれていた。本当にありがとう。
ただこの記事を見つけるのにかなり時間がかかったので、自分でも記事を書くことにした。誰かの役に立つと嬉しい。
cgroup バージョン確認
$ stat -fc %T /sys/fs/cgroup/
cgroup2fscgroup2fsになってるのを確認した
GRUB_CMDLINE_LINUX="systemd.unified_cgroup_hierarchy=0"
sudo update-grub
sudo reboot$ stat -fc %T /sys/fs/cgroup/
tmpfsv1に戻した。
勝利